What is the Robots.txt file
Think of a robots.txt file as a “Code of Conduct” sign posted on the wall of a gym, a bar, or a community center: the sign itself doesn’t have the power to enforce the listed rules, but “good” patrons will follow the rules, while “bad” ones are likely to break them and face consequences.
A bot is an automated computer program that interacts with websites and applications. There are good and bad bots, and a type of good bot is called a web crawler bot. These bots “crawl” web pages and index the content so it can appear in search engine results. A robots.txt file helps manage the activities of these web crawlers so they don’t overload the web server hosting the website, or index pages not meant for public view.
How a Robots.txt File Works
Search engines have two main jobs:
- Crawling the web to discover content
- Indexing that content so it can be served to searchers seeking information.
To crawl sites, search engines follow links to move from one site to another, crawling billions of links and websites. This crawling behavior is sometimes known as “spidering”.
After reaching a website, but before crawling it, the search crawler will look for a robots.txt file. If it finds one, the crawler will read that file first before continuing through the page. Because the robots.txt file contains information about how the search engine should crawl, the information found there will instruct further crawling action on this particular site. If the robots.txt file does not contain any directives prohibiting a user-agent’s activity (or if the site doesn’t have a robots.txt file), it will proceed to crawl other information on the site.
Why Robots.txt is Important
A robots.txt file helps manage the activities of web crawlers so they don’t overload your website or index pages not intended for public viewing.
Here are some reasons you might want to use a robots.txt file:
1. Optimize Crawl Budget
The “crawl budget” is the number of pages Google will crawl on your site at any given time. The number can vary based on the size, health, and backlinks of your site.
Crawl budget is important because if your site’s number of pages exceeds your site’s crawl budget, you will have pages on your site that are not indexed. And pages that are not indexed will not rank at all.
By blocking unnecessary pages with robots.txt, Googlebot (Google’s web crawler) can spend more crawl budget on important pages.
2. Block Duplicate and Non-Public Pages
You don’t need to allow search engines to crawl every page on your site because not all need to rank. Examples include staging sites, internal search result pages, duplicate pages, or login pages.
WordPress, for example, automatically disables /wp-admin/ for all crawlers.
These pages need to exist, but you don’t need them to be indexed or found on search engines. A perfect case to use robots.txt to block these pages from crawlers and bots.
3. Hide Resources
Sometimes, you’ll want Google to exclude resources like PDFs, videos, and images from search results. Maybe you want to keep those resources private or make Google focus on more important content. In that case, using robots.txt is the best way to prevent them from being indexed.
Other Important Aspects You Should Know About Robots.txt
- For it to be found, the robots.txt file must be located in the top-level directory of the website.
Robots.txt is case-sensitive: the file must be called “robots.txt” (not Robots.txt, robots.TXT, or otherwise). - Some user agents (bots) may choose to ignore your robots.txt file. This is especially common with more nefarious crawlers like malware bots or email address scrapers.
- The /robots.txt file is publicly accessible: simply add /robots.txt at the end of any root domain to view the directives of that website (if that site has a robots.txt file!). This means that anyone can see which pages you do or do not want to be crawled, so you should not use it to hide private user information.
- Each subdomain on a root domain uses separate robots.txt files. This means that both blog.example.com and example.com must have their own robots.txt files (at blog.example.com/robots.txt and example.com/robots.txt).
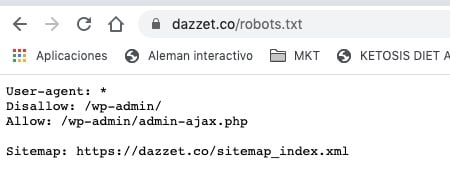
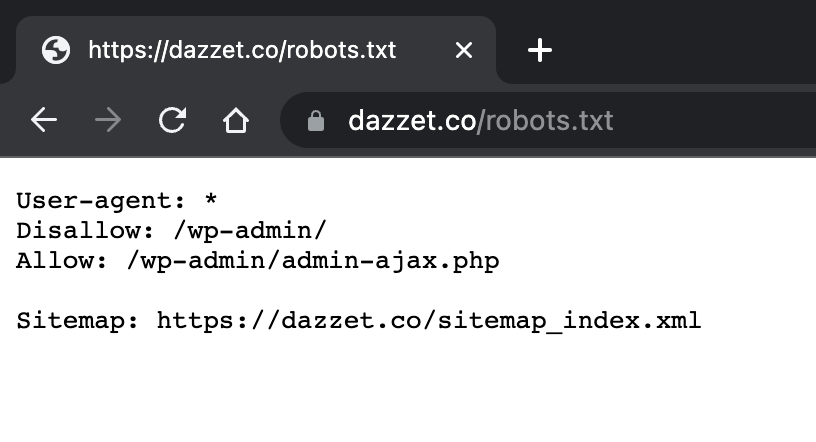
- In general, it’s good practice to indicate the location of any sitemap associated with this domain at the end of the robots.txt file. Here is an example.
Technical Syntax of Robots.txt
The syntax of robots.txt can be considered as the “language” of the robots.txt files. There are five common terms that you’ll likely encounter in a robots file. They include:
- User-agent: The specific web crawler you are giving crawling instructions to (usually a search engine). A list of most user agents can be found [here](https://www.robotstxt.org/db.html).
- Disallow: The command used to tell a user agent not to crawl a particular URL. Only one “Disallow:” line is allowed for each URL.
- Allow (only applicable for Googlebot): The command to tell Googlebot that it can access a page or subfolder even if its main page or subfolder is forbidden.
- Crawl-delay: How many seconds a crawler should wait before loading and crawling the content of the page. Note that Googlebot does not recognize this command, but the crawl rate can be set in Google Search Console.
- Sitemap: Used to indicate the location of any XML sitemap associated with this URL. Note that this command is only supported by Google, Ask, Bing, and Yahoo.
Where the Robots.txt File is Placed on a Website
When search engines and other web crawling robots (like Facebook’s robot, Facebot) arrive at a website, they look for a robots.txt file. However, they will only look for that file in a specific place: the main directory (usually your root domain or homepage). If a user agent visits www.example.com/robots.txt and does not find a robots file there, it will assume that the site does not have one and will proceed to crawl everything on the page (and perhaps even the entire site). Even if the robots.txt page existed at, for example, example.com/index/robots.txt or www.example.com/homepage/robots.txt, it would not be discovered by user agents and, therefore, the site would be treated as if it had no robots file at all.
To ensure your robots.txt file is found, always include it in your main directory or root domain.
Why You Need a Robots.txt File
Robots.txt files control crawler access to certain areas of your site. While this can be very risky if you accidentally prohibit Googlebot from accessing your entire site (!!), there are some situations where a robots.txt file can be very useful.
Some common use cases include:
- Preventing duplicate content from appearing in the SERPs (note that meta robots are usually a better option for this)
- Keeping entire sections of a website private (e.g., your engineering team’s test site)
- Preventing internal search results pages from appearing in a public SERP
- Specifying the location of a sitemap or multiple sitemaps
- Preventing search engines from indexing certain files on your website (images, PDFs, etc.)
- Specifying a crawl delay to prevent your servers from being overloaded when crawlers load multiple pieces of content at once
If there are no areas on your site that you want to control user agent access to, you might not need a robots.txt file at all.
SEO Best Practices
- Make sure you are not blocking any content or section of your website that you want to be crawled.
- Links on pages blocked by robots.txt will not be followed. This means that 1) unless they are also linked from other search engine accessible pages (i.e., pages not blocked through robots.txt, meta robots, or otherwise), the linked resources will not be crawled and may not be indexed. 2) No link equity can be passed from the blocked page to the link’s destination. If you have pages to which you want to pass equity, use a blocking mechanism other than robots.txt.
- Do not use robots.txt to prevent sensitive data (such as users’ private information) from appearing in the SERP results. Because other pages can link directly to the page containing private information (bypassing robots.txt directives on your root domain or homepage), it can still be indexed. If you want to block your page from search results, use a different method such as password protection or the meta noindex directive.
- Some search engines have multiple user agents. For example, Google uses Googlebot for organic search and Googlebot-Image for image search. Most user agents of the same search engine follow the same rules, so it is not necessary to specify directives for each of the multiple crawlers of a search engine, but having the ability to do so allows you to fine-tune how your site’s content is crawled.
- A search engine will cache the content of robots.txt, but typically updates cached content at least once a day. If you change the file and want to update it more quickly than it is happening, you can submit your robots.txt URL to Google.
Juan Esteban Yepes
